
Predictive maintenance has moved from experimental capability to a core operational requirement in modern data centers. As data center technology evolves toward higher power densities, mixed workloads, hybrid cooling architectures, and geographically distributed facilities, traditional maintenance models struggle to manage operational risk. Fixed-interval preventive maintenance and alarm-based reactive responses no longer provide sufficient protection against failure modes that develop gradually, interact across systems, and manifest under specific operating conditions.
Predictive maintenance addresses this gap by applying data-driven models to continuously assess asset conditions, quantify failure risk, and recommend targeted interventions. For data centers operating under strict availability, efficiency, and cost constraints, predictive maintenance now plays a central role in reliability engineering and operational decision-making.
This blog examines emerging predictive maintenance strategies for data centers, focusing on technical architecture, analytical models, and implementation considerations relevant to experienced practitioners.
What does predictive maintenance mean for data center Monitoring?
Predictive maintenance is the use of real-time and historical operational data to anticipate asset degradation and failure before functional loss occurs. Unlike preventive maintenance, which assumes a statistically averaged wear rate, predictive maintenance evaluates the actual condition of equipment under real operating loads, environmental conditions, and usage patterns.
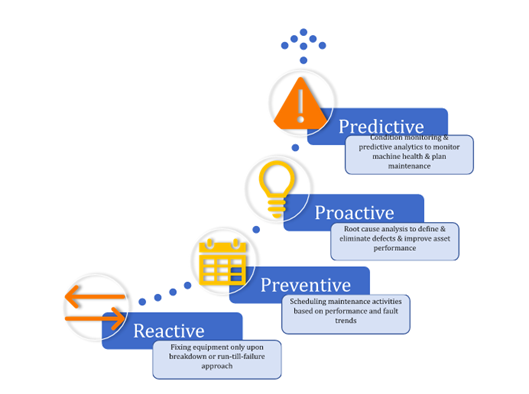
Source: Infinite Uptime- What is Predictive Maintenance (PdM) and how does it differ from Preventive Maintenance?
In data centers, predictive maintenance applies across multiple subsystems:
- Electrical infrastructure: UPS systems, batteries, switchgear, PDUs, transformers
- Mechanical systems: chillers, CRAC/CRAH units, pumps, compressors, cooling towers
- IT infrastructure: servers, storage, networking equipment
- Environmental systems: airflow management, humidity control, thermal containment
The complexity arises not from individual components, but from interdependencies between systems. A degradation event in cooling efficiency can elevate thermal stress on IT equipment, which in turn alters power draw profiles and stresses upstream electrical assets. Predictive maintenance must therefore operate across system boundaries rather than within isolated asset silos.
How do Traditional Maintenance Models Fail in Data Centers?
Preventive and reactive maintenance strategies fail primarily because they assume static operating conditions and independent asset behavior. According to the Uptime Institute’s 2021 Annual Outage Analysis, 37% of data center failures are due to power-related issues.
Reactive maintenance identifies failures after service impact occurs. In data centers, this approach directly translates into downtime, SLA violations, and emergency interventions.
Preventive maintenance schedules interventions based on time or usage thresholds, ignoring variability in load profiles, redundancy utilization, and environmental stress. This leads to two systemic inefficiencies:
- Premature maintenance on healthy assets
- Missed degradation in assets operating under abnormal conditions
Neither approach accounts for the non-linear degradation patterns common in power electronics, batteries, and cooling equipment.
Predictive maintenance replaces static assumptions with continuous condition assessment.
Why Predictive Maintenance Is Now Non-Negotiable
Data center operators face converging pressures:
- Higher power densities
- Increased energy cost volatility
- Reduced tolerance for downtime
- Growing infrastructure complexity
Predictive maintenance directly addresses these pressures by enabling early fault detection, targeted interventions, and system-level risk management. It reduces unplanned outages, extends asset life, and improves operational efficiency without relying on conservative over-maintenance.
For advanced data center operations, predictive maintenance is no longer just about optimization but the baseline for reliable, scalable operations.
Core Predictive Maintenance Architectures for Data Centers
Modern predictive maintenance strategies rely on layered technical architectures. Each layer supports increasingly advanced analytical capability.
1. High-Fidelity Data Acquisition
Predictive maintenance begins with data quality. Low sampling rates, aggregated metrics, and incomplete telemetry severely limit model accuracy.
Emerging data center monitoring architectures emphasize:
-
- Asset-level sensors for temperature, vibration, electrical parameters, and flow
- High-resolution time-series data rather than averaged values
- Synchronization across power, cooling, and IT telemetry
Without high-fidelity data, predictive models revert to threshold-based heuristics and lose predictive value.
2. Condition Monitoring and Feature Engineering
Raw sensor data rarely provides direct insight. Predictive maintenance systems derive secondary indicators that correlate more strongly with failure mechanisms, such as:
-
- Thermal gradients instead of absolute temperature
- Harmonic distortion trends rather than instantaneous current
- Rate-of-change metrics for voltage, pressure, or airflow
Feature engineering remains a critical engineering task. Poorly selected features produce false positives and unstable models, especially in environments with dynamic load behavior.
3. Predictive Maintenance Models for Data-Driven Decisions
Several predictive modeling approaches dominate current data center implementations. Each addresses different failure characteristics.
a. Time-Series Forecasting Models
Time-series models such as ARIMA, state-space models, and LSTM networks forecast expected system behavior based on historical patterns. Operators detect degradation when actual behavior diverges from forecasted baselines.
These models perform well for:
-
-
- Periodic thermal and load behavior
- Gradual efficiency degradation
- Predictable seasonal or workload-driven patterns
-
However, they struggle with rare failure modes unless combined with anomaly detection.
b. Anomaly Detection and Unsupervised Learning
Unsupervised models identify deviations from learned normal behavior without requiring labeled failure data. Common techniques include:
-
-
- Principal component analysis (PCA)
- Autoencoders
- Isolation forests
-
These models are valuable in data centers because many assets fail infrequently, which limits the amount of supervised training data. Anomaly detection identifies emerging risks early but requires careful tuning to avoid alert fatigue.
c. Physics-Informed Predictive Models
Purely data-driven models often lack robustness under unseen operating conditions. Physics-informed models embed thermodynamic, electrical, or mechanical constraints into machine learning frameworks.
Examples include:
-
-
- Thermal models constrained by airflow and heat transfer equations
- Battery degradation models incorporating electrochemical behavior
- Chiller performance models combining compressor physics with ML residuals
-
These hybrid approaches reduce false positives and improve extrapolation accuracy.
d. Remaining Useful Life (RUL) Estimation
RUL models estimate the time window before functional failure under current operating conditions. These models support:
-
-
- Maintenance scheduling optimization
- Spare parts planning
- Risk-based prioritization
-
In data centers, RUL estimation proves particularly effective for batteries, fans, pumps, and rotating equipment where degradation follows measurable trajectories.
Emerging Technologies in Predictive Maintenance that will benefit Data Centers
AI-Driven Predictive Maintenance for Data Centers
AI-driven predictive maintenance moves beyond threshold-based alerts by integrating multiple analytical techniques into a system-level decision framework. Instead of treating assets in isolation, AI models correlate electrical, mechanical, and IT data to understand how degradation in one domain influences overall availability and redundancy. These models assess asset behavior under real operating conditions and assign probabilistic risk scores that reflect both failure likelihood and operational impact.
Key capabilities include:
- Cross-asset correlation to detect cascading risk
- Continuous model retraining as loads and operating conditions evolve
- Context-aware alerts that account for redundancy state and criticality
This approach shifts maintenance planning from asset-centric inspection to system-centric reliability management.
Multisite Predictive Maintenance and Fleet Learning
As operators manage geographically distributed data centers, predictive maintenance increasingly operates at the fleet level. Multisite monitoring aggregates telemetry and maintenance data across facilities, enabling models to learn from a broader range of operating conditions and failure patterns. This approach improves prediction accuracy, particularly for rare or slow-developing failure modes.
Multisite predictive maintenance enables:
- Fleet-wide performance benchmarking
- Transfer learning across similar equipment types
- Early identification of systemic design or vendor-related issues
By pooling degradation patterns across sites, fleet learning accelerates model maturity and reduces time-to-value for new deployments.
Asset Performance Monitoring in Data Centers
Predictive maintenance is most effective when embedded within an asset performance monitoring (APM) framework. APM integrates real-time condition data, predictive analytics, maintenance history, and operational context to support structured decision-making. Rather than reacting to isolated alerts, teams evaluate asset health based on risk, criticality, and business impact.
This integration enables teams to:
- Rank assets by failure, risk and operational importance
- Align maintenance actions with availability and capacity objectives
- Track the effectiveness of interventions over time
APM elevates predictive maintenance from a diagnostic function to a strategic reliability and planning capability.
Learn more about Rugged Monitoring’s Enterprise APM Suite: RM EYE
Predictive maintenance has matured into a core operational discipline for data centers. Advances in data acquisition, analytics, and AI now allow operators to move beyond alarms and schedules toward continuous risk assessment and system-level reliability management.
As data center technology continues to evolve, predictive maintenance strategies that integrate condition monitoring, advanced modeling, and operational decision-making will define the difference between resilient infrastructure and fragile operations.
Book a Demo with our experts to transform your data center monitoring strategy


